

05/2022
Im Arbeitsverhältnis wird Voice Recognition als Arbeitsmittel, Leistungsmessung, Zugangskontrolle oder Gesundheitsindikator verwendet. Der Einsatz von Voice Recognition muss in datenschutzrechtlicher Hinsicht einen genügend hinreichenden Arbeitsplatzbezug aufweisen. Entscheidend ist in vielen Fällen die Verhältnismässigkeit der Bearbeitung und, insb. bei Cloud-Lösungen, die Wahrung der erforderlichen Datensicherheit. Ist eine Einwilligung des Arbeitnehmers vorausgesetzt, sind hohe Hürden an die Freiwilligkeit zu setzen. Zudem muss sie in den meisten Fällen ausdrücklich sein. Durch die Revision des Datenschutzgesetzes werden Regelungskonzepte wie das Profiling, die Datenschutz-Folgenabschätzung, automatisierte Einzelentscheidungen und technische Anforderungen von der europäischen DSGVO übernommen. Allerdings bringt die Schweizer Ausgestaltung keine in der Praxis relevanten Änderungen im Zusammenhang mit Voice Recognition mit sich.
I. Einführung
Während die technologische Ausschöpfung unserer Stimme noch vor wenigen Jahren lediglich aus dem Genre Science‑Fiction zu vernehmen war, so lässt sie sich heute ganz gezielt nutzen und einsetzen. Zwangsläufig erhält die unter dem Stichwort «Voice Recognitio» geläufige Technologie auch Einzug in die Arbeitswelt 4.0 Mittlerweile können Computer mittels Spracherkennung die Befehle von Arbeitnehmern genau verstehen und ausführen. Dabei sind die Einsatzbereiche von Voice Recognition äusserst vielfältig. Dokumentation und Transkription ordnen sich noch unter den eher simplen Arbeitsmitteln ein. Lernbasierte Sprachassistenten vermögen dahingegen den Arbeitnehmer nicht nur zu unterstützen, sondern analysieren die persönliche Arbeitsweise ihres Benutzers und errechnen individuelle Handlungsvorschläge. Weiter greifen sog. People Analytics Programme auf Stimm- und Sprachdaten zurück, indem sie bspw. Verhaltenscharakteristiken von Bewerbern auswerten. Die v.a. aus Call-Centern bekannte Methode des Keyword Spotting erkennt verkaufsfördernde und kritische Schlüsselwörter oder analysiert zusätzlich die Stimmung des Agenten während des Gesprächs. Über die Stimme lässt sich darüber hinaus eine Zugangskontrolle über kritische Informationen und Ressourcen etablieren. Ferner ermöglicht die Stimmanalyse die frühzeitige Erkennung von Krankheiten oder die Messung der Stressbelastung am Arbeitsplatz.
Gleichzeitig gewährt die Stimme aber auch Einblick in die Persönlichkeit einer Person. Durch sie lässt sich eine Person eindeutig identifizieren und sie verrät vieles über die Charaktereigenschaften, das Verhalten und die Gesundheit. Dadurch wird eine Fülle an Daten erhoben und bearbeitet, was eine Gefahr für das individuelle Recht auf informationelle Selbstbestimmung darstellt, welches wiederum als «raison d’être» des Datenschutzrechts gilt. Nach einem langandauernden Revisionsprozess steht seit 25. September 2020 nun die definitive Fassung des revidierten Datenschutzgesetzes bereit, welches sich dem Schutzniveau der europäischen DSGVO angleichen und hinsichtlich moderner automatisierter Datenbearbeitungen mehr Rechtssicherheit bieten soll. Die folgende Analyse der Voice Recognition nimmt sich den datenschutzrechtlichen Neuerungen sogleich an.
II. Grundlagen der Voice Recognition
1. Definition
Voice Recognition ist eine Sammelbezeichnung für Technologien, die einen Sprecher anhand stimmspezifischer Merkmale identifizieren (Stimmerkennung), den linguistischen Inhalt aus natürlich gesprochener Sprache extrahieren (Spracherkennung) oder aufgrund der Stimme Rückschlüsse auf den Charakter, emotionalen Zustand oder Wahrheitsgehalt ziehen (Stimmanalyse).
Die Stimmerkennung unterteilt sich wiederum in die Sprecherverifikation, bei der nur eine binäre Entscheidung getroffen wird (gesuchter Sprecher: ja – nein) und die Sprecheridentifikation, wobei eine Vielzahl an möglichen Ergebnissen vorliegt.
Im Zuge der Spracherkennung können gleichzeitig sprecherspezifische Eigenschaften, wie bspw. Wortwahl oder Sprechgeschwindigkeit identifiziert werden, die zur Sprecheridentifikation bzw. -verifikation oder Stimmanalyse angewendet werden können. Auch Kombinationen aus Stimm- und Spracherkennung sind denkbar, bspw. ein Mobiltelefon, das lediglich auf Sprachbefehle des Besitzers reagiert. Letztlich ist der Stimmanalyse insofern eine Zwischenstellung zwischen der Stimm- und Spracherkennung beizumessen, als sie sowohl stimm- als auch sprachspezifische Merkmale analysiert, dabei aber einen eigenständigen Zweck verfolgt.
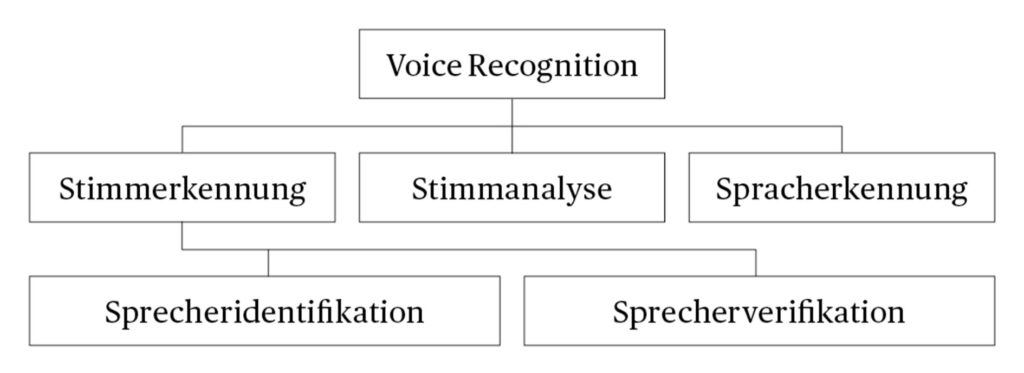
Abbildung 1 Begriffliche Systematik der Voice Recognition
2. IT-Infrastruktur und Rechtsbeziehungen
Je nach Ausgestaltung der IT-Infrastruktur eines Voice Recognition Systems liegen verschiedene Rechtsbeziehungen vor. Bei Cloud-Lösungen wird die vertraglich vereinbarte Software über eine Applikation oder einen Browser unmittelbar in der Datenwolke ausgeführt (Software as a Service). Die Spracheingaben werden an einen Server übermittelt und analysiert, worauf die entsprechenden Befehle an das System retourniert werden. Zwischen der Arbeitgeberin und dem Cloud-Provider muss eine Vereinbarung nach den Bestimmungen der Datenbearbeitung durch Dritte (Art. 10a DSG) bestehen. Der Cloud-Provider kann zur Erbringung seiner Leistung auf die Infrastruktur, wie Netzwerk, Server oder Speicher, von Subunternehmern zurückgreifen.
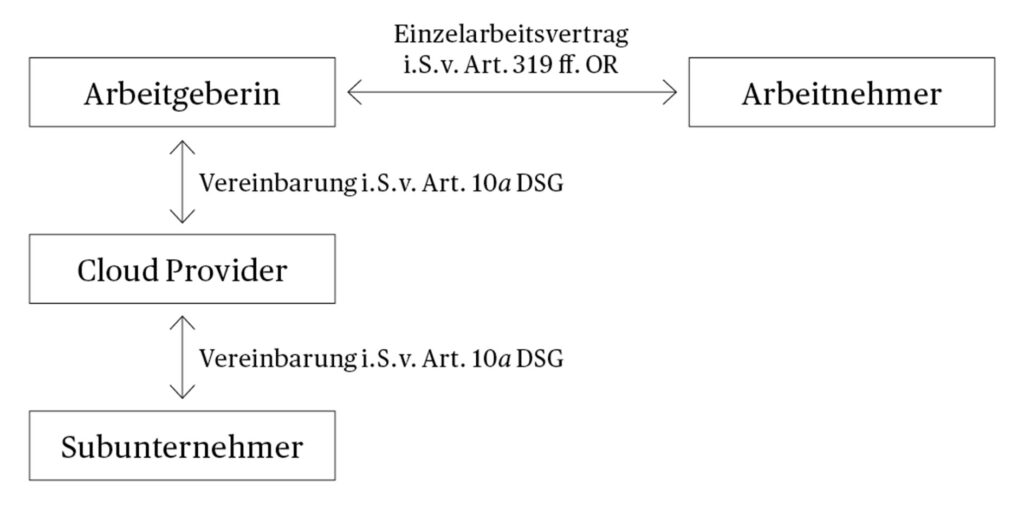
Abbildung 2 Vertragsbeziehungen Cloud Lösung
Bei reinen Offline-Lösungen findet die Bearbeitung stationär durch eine fest installierte Software statt. Offline-Lösungen sind v.a. in traditionell ausgestalteten Systemen vorherrschend oder wo hohe Anforderungen an die Datensicherheit gestellt werden. Aufgrund der tieferen Leistungsfähigkeit und tendenziell höheren Kosten von Offline-Lösungen werden i.d.R. Cloud-Lösungen bevorzugt. Je nach Ausgestaltung des konkreten Vertragsgegenstandes zwischen der Arbeitgeberin und dem Softwareentwickler kann ein Nominat- oder Innominatkontrakt vorliegen. Entscheidend ist, dass aufgrund der lokalen Bearbeitung der Daten keine Datenbearbeitung Dritter vorliegt.
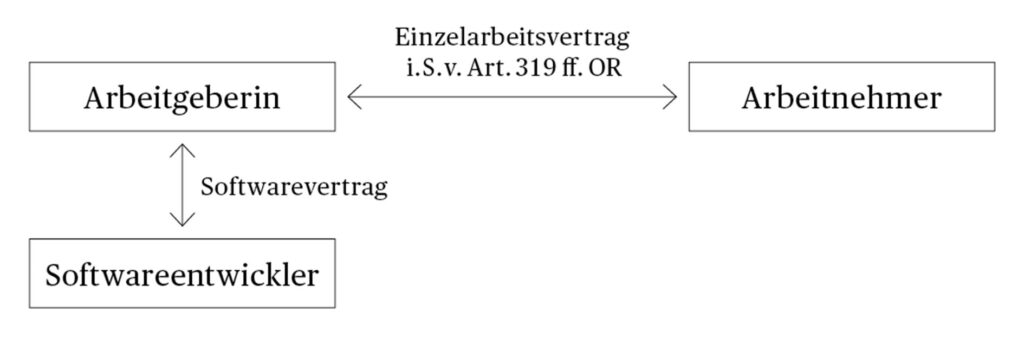
Abbildung 3 Vertragsbeziehungen Offline-Lösung
III. Voice Recognition im Geltungsbereich des Datenschutzrechts
1. Qualifikation von Stimm- und Sprachdaten
Eine fundamentale Unterscheidung beim Einsatz von Voice Recognition ist, ob das System Stimm– oder Sprachdaten bearbeitet. Die Stimme ist ein biometrisches Merkmal und weist als solches in jedem Fall einen Personenbezug auf. Während biometrische Daten unter dem gegenwärtigen DSG grundsätzlich als «gewöhnliche» Personendaten zu qualifizieren sind, gelten sie unter dem revidierten Datenschutzgesetz als besonders schützenswerte Personendaten, wenn sie eine Person eindeutig identifizieren. Diese Formulierung dürfte schon aufgrund der technischen Unmöglichkeit nicht so zu verstehen sein, dass das angewandte Verfahren eine hundertprozentige Sicherheit der Identifikation bewerkstelligt. Vielmehr bemisst sich der Erfolg des technischen Verfahrens anhand eines vordefinierten Schwellenwertes (threshold). So sind Aufnahmen der Stimme als biometrische Daten zu qualifizieren, wenn das Verfahren dem Zwecke der Identifikation dient.
Lassen Stimmdaten Rückschlüsse auf die Gesundheit oder Rassenzugehörigkeit zu, so können bereits unter geltendem Recht besonders schützenswerte Daten vorliegen. Entscheidend sind die Geeignetheit der Daten und der Bearbeitungszweck. Werden Anzeichen einer Depression diagnostiziert, liegen Gesundheitsdaten vor, hingegen genügen temporäre Gemütszustände oder der Wahrheitsgehalt einer Aussage nicht. Zudem können Unterschiede in Aussprache, Wortwahl, Dialekt und syntaktischen Strukturen mit geografischen und sozialen Faktoren und letztlich der Rasse i.S.v. Ethnizität in Verbindung gebracht werden.
Die Sprache– im Gegensatz zur Stimme – ist primär ein Medium, das dem Informationstransfer dient. Diese Informationen sind als (besonders schützenswerte) Personendaten zu qualifizieren, wenn sie die gesetzlichen Anforderungen erfüllen. Zu beachten ist jedoch, dass die Natur der Daten nicht im Voraus erkennbar und dementsprechend keine separate Bearbeitung realisierbar ist, womit konsequenterweise für sämtliche Sprachdaten der strengere Massstab der besonders schützenswerten Personendaten angelegt werden muss. Fraglich ist allerdings, ob die Sprache an sich ein Personendatenwert sein kann. In der Regel werden Sprachdaten durch ein auf den Arbeitnehmer zurückzuführendes Endgerät bearbeitet. Folglich lassen sich die Daten regelmässig einer bestimmten Person zuordnen, wodurch ein Personenbezug anzunehmen ist. Dies gilt umso mehr für internetfähige Endgeräte, welche eine einmalige IP-Adresse besitzen.
Ausserdem ist im Kontext von «Big Data» und «People Analytics» für einen weiten Anwendungsbereich des DSG zu plädieren. Moderne technische Möglichkeiten erlauben selbst bei eigentlich anonymisierten Daten eine Re‑Identifizierung. Insofern ist es schwer denkbar, dass man sich in der Bearbeitung von Stimm- und Sprachdaten ausserhalb des Geltungsbereiches des DSG bewegt.
2. Persönlichkeitsprofile / Profiling
Unter der Revision des DSG ersetzt das Profiling das bisherige Persönlichkeitsprofil. Profiling setzt eine automatisierte Bearbeitung voraus, auf deren Basis persönliche Aspekte der betroffenen Person vorhergesagt oder beurteilt werden.
Das rDSG folgt einem risikobasierten Ansatz, sodass nur an Profiling mit hohem Risiko strengere Rechtsfolgen zu knüpfen sind. Ein solches liegt vor, wenn es mit einem hohen Risiko für die Persönlichkeit oder Grundrechte der betroffenen Person verbunden ist. Dies ist wiederum nichts anderes als das Persönlichkeitsprofil unter geltendem Datenschutzrecht.
Die Bearbeitung von Sprach- und Stimmdaten erfolgt bei Voice Recognition naturgemäss automatisiert. Spracherkennende Systeme betreiben Profiling, wenn persönliche Aspekte des Nutzers bewertet werden. Sprachassistenten können den Arbeitnehmer mitunter bezüglich Interessen, beruflichen Schwerpunkten und persönlichen Präferenzen analysieren und ggf. darauf basierend selbständige Handlungen vornehmen. Profiling im Rekrutierungsprozess liegt vor, wenn Charakterzüge, der emotionale Zustand oder die Arbeitsweise des Bewerbers analysiert werden. Stimmanalysierende Zutrittskontrollen betreiben nur Profiling, wenn die Anzahl der Zutrittskontrollen griffige Rückschlüsse auf den Bewegungsablauf, das Verhalten oder den Aufenthaltsort eines Arbeitnehmers ermöglichen.
Offen bleibt, ob durch das Profiling Persönlichkeitsprofile entstehen, die zu einem hohen Risiko für die betroffene Person führen. Dies hängt wiederum von den im konkreten Fall getroffenen Schutzmassnahmen ab.
IV. Ausgewählte datenschutzrechtliche Problemfelder
1. Bearbeitung innerhalb des arbeitsrelevanten Bereichs
Der Datenschutz ist in seiner Natur vordergründig Persönlichkeitsschutz. Gemäss Art. 328b OR liegt im Arbeitsverhältnis eine persönlichkeitsverletzende Datenbearbeitung vor, wenn sie über den für das konkrete Arbeitsverhältnis relevanten Bereich hinaus geht.
Der wohl herrschende Teil der Lehre betrachtet die Norm als Verbotsnorm, was ein Durchbruch zum Prinzip der grundsätzlichen Erlaubnis mit Verbotsvorbehalt aufzufassen ist. Die Berufung auf einen Rechtfertigungsgrund i.S.v. Art. 13 DSG wäre folglich nicht möglich. Nach einer liberaleren und hier vertretenen Ansicht ist Art. 328b OR als ein auf das Arbeitsverhältnis beschränkter Bearbeitungsgrundsatz zu verstehen, der den Grundsatz der Verhältnismässigkeit konkretisiert. In diesem Sinne ist eine Verletzung von Art. 328b OR ebenso durch einen Rechtfertigungsgrund heilbar.
Ein Arbeitsplatzbezug ist insb. bei der Verwendung von Spracherkennung als Arbeitsmittel zu bejahen. Beim Keyword Spotting oder der Stimmanalyse ist ein solcher ebenfalls zu vermuten, sofern sich die Analyse der Leistung oder des Verhaltens betrieblich begründen lässt. Dabei ist aber insb. zu berücksichtigen, wie flächendeckend solche Analysen durchgeführt werden, ob auch private Unterhaltungen ausgewertet werden und ob die Analyse dem Arbeitnehmer bekannt ist.
Charaktereigenschaften wie Belastbarkeit, Teamfähigkeit oder Kommunikationsfähigkeit zählen zu den beruflichen Qualifikationen, weshalb bei Stimm- und Sprachanalysen im Bewerbungsverfahren ebenfalls ein Arbeitsplatzbezug zu vermuten ist. Die Analyse weiterer Charaktereigenschaften, die der persönlichen Qualifikation zuzurechnen sind, kann sich im konkreten Fall ebenfalls aufdrängen, besonders wenn dies aufgrund von Haftungs- und Reputationsrisiken geboten ist. Dieselben Überlegungen sind auch während des Arbeitsverhältnisses anzustellen. Anders ist die Rechtslage hingegen, wenn anhand von bestehenden Schlüsselmitarbeitern ein Wunschprofil als Referenz für Bewerbende erstellt wird. In diesem Fall erfolgt die Bearbeitung nicht im Zusammenhang mit dem persönlichen Arbeitsverhältnis.
Biometrische Stimmdaten, die zur Identifikation oder Verifikation verwendet werden, weisen einen Arbeitsplatzbezug auf, sofern sie für Sicherheitszwecke notwendig sind. Werden anhand von Stimmdaten Krankheiten diagnostiziert, liegt i.d.R. kein Arbeitsplatzbezug vor.
2. Arbeitnehmerüberwachung
Das Abhören und die Aufnahme fremder Gespräche ist gemäss Art. 179bis StGB verboten. Die Norm dürfte allerdings im Zusammenhang mit Voice Recognition kaum einschlägig sein. Zunächst wäre im Einzelfall zu klären, ob die registrierte Sequenz überhaupt ein Gespräch i.S. eines Gedanken- und Informationsaustausches darstellt. Die definitionsgemäss vorausgesetzte Einwilligung kann ausdrücklich oder stillschweigend erfolgen, wodurch sie sich bereits konkludent durch die Aktivierung des entsprechenden Systems ergibt. Bei fortlaufend aktiven Systemen kann die Einwilligung auch in Form einer arbeitsvertraglichen Klausel vorliegen. Zudem schränkt Art. 179quinquies Abs. 1 StGB den Anwendungsbereich von Art. 179bis StGB zusätzlich ein.
Relevanter dürfte Art. 26 ArGV 3 sein, der den Einsatz von Überwachungs- und Kontrollsystemen verbietet, sofern sie nicht aus anderen Gründen, wie namentlich zur Sicherheits- oder Leistungsüberwachung, erforderlich sind. Solche Systeme dürfen die Gesundheit und Bewegungsfreiheit der Arbeitnehmer nicht beeinträchtigen. Die Abgrenzung von zulässigen und unzulässigen Systemen ist bisweilen problematisch, zumal Leistung und Verhalten stark miteinander verknüpft sind. Die Zulässigkeit ist letztlich von der Verhältnismässigkeit (Art. 4 Abs. 2 DSG) der konkreten Einsatzweise abhängig und inwieweit die Arbeitgeberin berechtigte Betriebsinteressen geltend machen kann. Liegen besonders schützenswerte Daten vor, ist grundsätzlich Zurückhaltung gefragt. In jedem Fall ist die Datenbearbeitung auf den konkreten Informationsbedarf der Arbeitgeberin zu beschränken und die Arbeitnehmer vorgängig anzuhören (Art. 5 und 6 ArGV 3).
Sprachgesteuerte Systeme sind regelmässig durch Produktivitätsgewinne rechtfertigbar. Hingegen sind sie unzumutbar, wenn sie gleichzeitig die Identität oder Gemütslage analysieren oder generell lückenlos aufzeichnen, was auch private Unterhaltungen beinhalten kann.
Das Verhalten des Arbeitnehmers gegenüber Kunden oder Geschäftspartnern stellt grundsätzlich eine zulässige Leistungskontrolle dar. Erfolgt nun aber eine Stimmanalyse oder Keyword Spotting andauernd und lückenlos, liegt ein unzulässiges Überwachungssystem vor. Es ist allerdings zu beachten, dass die Arbeitgeberin ein berechtigtes Interesse daran hat, die Leistung der Arbeitnehmer zu überwachen. Es ist deswegen erforderlich, die Zwecke der eingesetzten Systeme genau zu bestimmen und nicht erforderliche Datenbearbeitungen klar abzugrenzen. M.a.W. kommt dem Grundsatz der Zweckbindung (Art. 4 Abs. 3 DSG) grosse Bedeutung zu. In der Bewerbungsphase gesammelte Stimm- und Sprachdaten dürfen nicht zur Persönlichkeitsdurchleuchtung oder für das anschliessende Arbeitsverhältnis verwendet werden, wenn dies nicht vom Bewerber akzeptierten Zweck gedeckt ist. Allgemein dürfen Stimm- und Sprachdaten nicht über längere Zeit systematisch gesammelt und verwaltet werden (sog. Data Warehousing) oder ggf. mit anderen Daten kombiniert werden (sog. Data Mining). Entstehen dadurch neue sog. Sekundärdaten, werden diese i.d.R. nicht vom ursprünglich angegebenen Zweck erfasst, zumal dieser bei der Datenbeschaffung gar nicht ersichtlich sein konnte.
Zugangskontrollen, die mittels Stimmerkennung Stimmdaten bearbeiten, sind so zu gestalten, dass keine Erstellung eines Verhaltensprofils des Arbeitnehmers möglich ist, d.h. keine detaillierten Bewegungsabläufe ersichtlich sind. Zugangskontrollen sind auf sensible Räumlichkeiten und Ressourcen zu beschränken. Weiter ist von einer zentralen Speicherung von biometrischen Daten abzusehen. Denkbar ist die Hinterlegung des Stimmabdrucks auf einer Smartcard oder dem dienstlichen Mobiltelefon. Überdies sind Systeme vorzuziehen, die keine abschliessende Identifikation vornehmen, sondern durch anonymisierte Daten abgleichen, ob der konkrete Mitarbeiter zum Kreis der berechtigten Personen gehört.
3. Verlust von Arbeitnehmerdaten
Die Anwendung von Voice Recognition stellt die Datensicherheit in verschiedener Hinsicht vor Herausforderungen. Namentlich bei Sprachassistenten, die sich durch einen Schlüsselbegriff aktivieren und daher permanent aufzeichnen, besteht ein gewisses Abhör- und Manipulationsrisiko.
Der Datenschutz soll den Einsatz von Cloud-Lösungen nicht unnötig beschränken. Regelmässig ist die Auslagerung gar wünschenswert, namentlich wenn der Cloud-Provider spezialisierte Ressourcen zur Erfüllung der datenschutzrechtlichen Anforderungen aufweist. Es ist indes zu beachten, dass die Auslagerung in die Cloud einen Kontrollverlust über die Daten mit sich bringt. Es obliegt somit der Verantwortung der Arbeitgeberin, den Cloud-Provider entsprechend auszuwählen, die richtigen Instruktionen zu erteilen und zu überwachen. Die zu treffenden Massnahmen hängen im Einzelfall von der Arbeitgeberin, der Sensitivität der Daten sowie der Organisation der eingesetzten Cloud-Lösung ab. Werden Daten verschiedener Nutzer in der Cloud ungenügend isoliert, steigt das Risiko für Konsolidierungsschäden, wie Distributed Denial of Services oder Hacker-Attacken. Der Cloud-Provider muss die Datenbearbeitungen verschiedener Cloud-Nutzer strikt voneinander getrennt ausführen und darum besorgt sein, dass es zu keiner Durchmischung der Daten kommt. Es empfiehlt sich deswegen, Datenschutz-Qualitätszeichen oder Zertifizierungen zu berücksichtigen und im Rahmen der Auftragsdatenbearbeitung festzuhalten, dass der Cloud-Provider die angemessenen Massnahmen im Rahmen des Gesetzes kennt und erfüllt. Tritt dennoch ein ungewollter Verlust oder eine Offenlegung von Daten ein, so lässt sich eine Informationspflicht aus dem Grundsatz von Treu und Glauben ableiten.
Biometrische Daten bergen zudem die latente Gefahr des Identitätsdiebstahls. Der Grundsatz der Datensicherheit muss auf allen Ebenen eines Erkennungssystems beachtet werden. Voice-Recognition-Systeme sollten lediglich die zum Identifikationsabgleich erforderlichen Merkmale extrahieren, die Rohdaten aber wieder vernichten. Im Weiteren sollten die Daten nur komprimiert und/oder verschlüsselt bearbeitet werden. Zudem ist, wenn immer möglich, eine dezentrale Speicherung der Daten zu bevorzugen.
4. Datenrichtigkeit
Die Arbeitgeberin ist gem. Art. 5 Abs. 1 DSG verpflichtet, die Richtigkeit der Daten sicherzustellen. Die digitale Verarbeitung der Sprache und Stimme ist ein komplexer Vorgang, bei dem an verschiedenen Stellen Fehler auftreten können, was konsequenterweise zu unrichtigen Daten führt. Zudem sind die der Voice Recognition zugrundeliegenden Algorithmen oft so komplex, dass ein allfälliger Fehler in der Bearbeitung im Nachhinein kaum rekonstruierbar ist (Black-Box-Problematik). Präventiv wirkende technische Massnahmen dürften daher vermehrt in den Vordergrund rücken.
Sprachassistenten können Eingaben falsch verstehen und in der Folge falsche Präferenzen für den Arbeitnehmer ableiten. Ein Assistent sollte demnach so gestaltet sein, dass falsche Eingaben unkompliziert bspw. im Nutzerprofil abgeändert oder gelöscht werden können.
Obschon ein tendenziell konstantes biometrisches Merkmal, kann sich die Stimme im Laufe der Zeit verändern. Es ist deswegen eine angemessene Akzeptanzschwelle (threshold) zu definieren und der Stimmabdruck in regelmässigen Abständen zu aktualisieren. In diesem Zusammenhang bieten Cloud-Lösungen den Vorteil einer fortlaufenden Echtzeitanalyse (continuous real-time analysis), wodurch die Stimmdaten in einem dynamischen Prozess aktualisiert werden.
Der Einsatz von Cloud-Lösungen entbindet die Arbeitgeberin nicht von der Gewährleistung der Datenrichtigkeit. Es scheint aber angebracht, den Cloud-Betreiber, der regelmässig über sämtliche Daten verfügt, im Rahmen der Auftragsdatenbearbeitung entsprechend zu beauftragen.
Remo R. Schmidlin; Voice Recognition im Arbeitsverhältnis — eine datenschutzrechtliche Analyse; sui generis, Zürich; 2022
https://doi.org/10.21257/sg.201
https://creativecommons.org/licenses/by-sa/4.0/
Zur einfacheren Lesbarkeit wurden die Quellenverweise und Fussnoten entfernt.