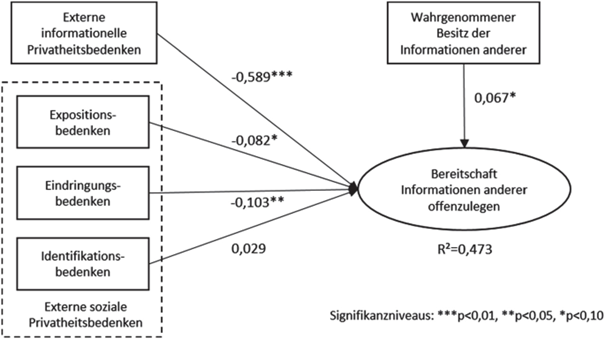
3 Wirkungen der DSGVO: Innovation, Wettbewerbsfähigkeit und Sanktionen
3.1 Datenschutz, Wettbewerbsfähigkeit und Innovation
Empirische Forschung zu den Innovationsauswirkungen von Regulierung im Allgemeinen (und von Datenschutzregulierung im Besonderen) liegt soweit nur begrenzt vor. Bisherige Arbeiten haben sich vor allem auf die Auswirkungen von Umweltverordnungen konzentriert, mit mehreren Ergebnissen, die für die Debatte um die DSGVO relevant sind und im Folgenden knapp zusammengefasst werden. Zum einen kann die in der öffentlichen Debatte häufig vertretene These, dass Regulierung grundsätzlich Innovationen hemme, so nicht bestätigt werden. Im Gegenteil haben statistische Studien wiederholt positive Korrelationen zwischen Innovationsintensität und der Strenge von Umwelt- und Verbraucherschutzregulierungen identifiziert. Von naiven Interpretationen dieser Ergebnisse, wonach mehr Regulierung zu mehr Innovation führt, ist natürlich abzusehen; zumal sich zahlreiche Fallstudien finden, die zeigen, dass Regulierung durchaus Technologieentwicklung blockieren kann. Jedoch zeigen sie, dass die tatsächlichen Wechselwirkungen zwischen Regulierung und Innovation (sowie Wettbewerbsfähigkeit im weiteren Sinne) komplexer sind als häufig angenommen wird.
Auf der negativen Seite kann man mindestens zwei Wirkmechanismen identifizieren, wie Regulierung Innovation blockieren kann: Zum einen aufgrund des Compliance-Aufwandes gestiegene Kosten, welche (rein rechnerisch) die für Innovationsausgaben zur Verfügung stehenden Ressourcen schmälern, bzw. den Profitabilitätsgrad, welchen die Innovation erzielen muss um sich betriebswirtschaftlich zu lohnen, steigert. Zum anderen führen direkte Verbote bestimmter Anwendungen oder Prozesse dazu, dass sich die ihnen zugrunde liegenden technischen oder organisatorischen Neuerungen nicht entfalten können. Weniger häufig in der Literatur diskutiert, für die Frage der DSGVO aber hoch relevant, ist ein dritter Faktor: die Rechts(un)sicherheit. Wenn Firmen nicht sicher sein können, ob ein Innovationsvorhaben erlaubt ist, werden sie es im Zweifel aufgeben, um Fehlinvestitionen zu vermeiden.
Umgekehrt beschreibt die Literatur aber auch Mechanismen, über welche Regulierung Innovation und sogar Wettbewerbsfähigkeit stimulieren kann. Insofern Regulierung Firmen Auflagen macht, besteht ein Anreiz, technische oder organisatorische Lösungen (d. h. Innovationen) zu entwickeln, um diese Auflagen zu erfüllen. Regulierung kann damit Märkte für neue Lösungen oder Produkte schaffen. Insofern die fragliche Regulierung später von anderen Ländern übernommen wird können sich dadurch Export- und Wettbewerbsvorteile für heimische Firmen ergeben. Ein weiterer möglicher innovationsfördernder Mechanismus von Regulierung liegt in dem Vertrauen, das Regulierung schaffen kann. Je größer das potentielle Risiko, dem sich Verbraucher mit der Nutzung eines Produktes ausgesetzt fühlen, desto höher ihre vermutlichen Hemmungen, das Produkt tatsächlich zu nutzen. Dies dürfte insbesondere für neue, komplexe Technologien gelten, bei denen Verbraucher glauben, sie unzureichend zu verstehen oder meinen, nicht genug Erfahrungswerte zu besitzen, um Risiken einschätzen zu können. Insofern (Risiko-)Regulierung Verbrauchern glaubhaft beteuern kann, etwaige Risiken einzudämmen, kann sie deren Bereitschaft, neue Technologien zu nutzen, erhöhen und damit letztlich den Markt und die Anreize zur Innovation neuer Technologien stärken.
In Summe ist also zu konstatieren, dass die möglichen Auswirkungen von Regulierung auf Innovation vielschichtig und gegenläufig sein können. Bislang konnten keine allgemeingültigen Gesetzmäßigkeiten darüber identifiziert werden, wann und unter welchen Umständen Regulierung Innovation eher positiv bzw. negativ beeinflusst. Tatsächlich ist davon auszugehen, dass auch keine solchen Gesetzmäßigkeiten existieren, sondern dass die jeweiligen Auswirkungen auf spezifische, nur schwer verallgemeinerbare Wechselwirkungen zwischen den spezifischen Rechtsvorschriften und den Besonderheiten der jeweiligen Technik zurückgehen.
Wie sieht es nun bei der DSGVO aus? Zeigt sie eher innovationsfördernde oder -hemmende Wirkungen? Diese Frage ist leider immer noch nur sehr bedingt zu beantworten, da soweit nur eine geringe Zahl meist kleinerer Studien und Erhebungen zu diesem Thema vorliegt. Es fehlen weiterhin größere quantitative Untersuchungen, die es erlauben würden, Auswirkungen verlässlich und nach Strukturmerkmalen (Unternehmensgröße, Branche, Geschäftsmodell, Verarbeitungskontext etc.) aufgeschlüsselt nachzuzeichnen und die zu Grunde liegenden Wirkmechanismen klar zu identifizieren.
Zunächst ist zu konstatieren, dass Untersuchungen aus dem ersten Jahr nach Verabschiedung der DSGVO (2017) eher auf (wenn auch verhalten) positive Auswirkungen hindeuteten. Ein Bild das sich in folgenden Jahren allerdings eintrübt. So stellen Martin u. a. in Interviews mit Unternehmensgründern und auf Datenschutz spezialisierten Rechtsanwälten (N = 19) fest, dass die DSGVO (zumindest bei den interviewten Firmen) anscheinend nur in wenigen Fällen zur Aufgabe geplanter neuer Produkte oder Features führte. Umgekehrt hatten die meisten dieser Firmen aufgrund der DSGVO neue Technologien zur Unterstützung von Datensicherheits- und Datenschutz-Compliance eingeführt. Insofern alle der interviewten Firmen datenintensive Dienste anboten, mit besonders sensiblen Daten arbeiteten oder risikoreiche Verarbeitungen durchführten, kann dieses Ergebnis als Hinweis gewertet werden, dass die DSGVO zumindest keine unmäßig innovationshemmenden Wirkungen entfaltete. Ganz im Gegenteil hat sie die Entwicklung von Märkten für neue Produkte und Lösungen angestoßen, wirkte also durchaus innovationsfördernd.
Der letzte Punkt, die Entstehung neuer Märkte für Produkte und Technologien um Datenschutz umzusetzen, wird auch durch entsprechende Branchenregister bestätigt, die seit 2017 kontinuierliches und rasches Wachstum in der Zahl der einschlägigen Firmen nachweisen. Innovationsaktivitäten fokussieren sich auf ein breites Spektrum von Lösungen, von Produkten zur Governance von Datenbeständen und Datenschutz-Management über IT-Sicherheit bis zu Verfahren zur Anonymisierung bzw. Pseudonymisierung von Daten und deren Auswertung.
Unglücklicherweise legen die wenigen verfügbaren quantitativen Erhebungen nahe, dass die Erfahrungen der Firmen seitdem negativer geworden sind, wobei das Gesamtbild nichtsdestotrotz widersprüchlich bleibt. Abb. 1 und 2 zeigen Ergebnisse aus mehreren repräsentativen Erhebungen des IT-Branchenverbands Bitkom. Demnach ist die Zahl der Unternehmen, welche die DSGVO als „einen Wettbewerbsvorteil für europäische Unternehmen“ sehen, seit 2017 kontinuierlich gestiegen, um mehr als die Hälfte: von nur 38 % auf 62 %. Paradoxerweise ist der Anteil der Firmen, die sagen, die DSGVO „bring[e] [ihrem eigenen] Unternehmen Vorteile“ ebenso stetig gefallen, ebenfalls um fast die Hälfte: von 39 % in 2017 auf 20 % in 2020. Gleichzeitig ist die Zahl der Firmen, die angaben, die DSGVO stelle „eine Gefahr für [ihr] Geschäft dar“ fast konstant geblieben, bei jeweils etwa 13 % (Abb. 1).
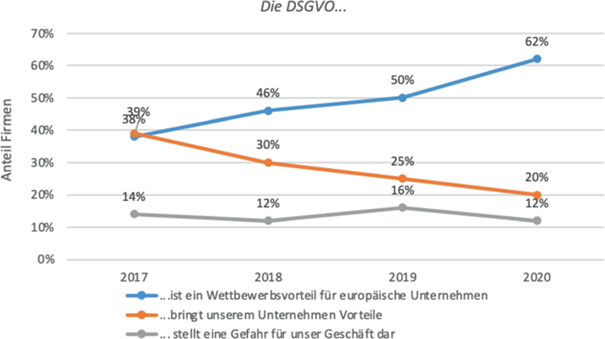
Abb. 1
(Quelle: Bitkom (2017, 2018, 2019, 2020))
Datenschutz und Wettbewerbsfähigkeit.
Auch die Aussagen zu den spezifischen Auswirkungen auf Innovation sind widersprüchlich. Einerseits ist die Zahl derer, die glauben, die DSGVO „verhinder[e] Innovationen in der EU“ leicht gefallen, von 37 % auf 29 %. Andererseits ist die Zahl derer, die angaben, dass „neue, innovative Projekte [in ihrem eigenen] Unternehmen aufgrund der DSGVO gescheitert sind“ von lediglich 14 % im Jahr 2019 auf volle 56 % im Jahr 2020 hochgeschnellt (Abb. 2). Eine Umfrage des Wirtschaftsforschungsinstituts ZEW unter Firmen der Informationswirtschaft kommt zu ähnlichen Ergebnissen: bei 24 % hat die DSGVO „Innovationen gebremst“, bei 13 % den „Einsatz neuer Technologien erschwert oder verhindert“. Im Android App-Markt (Google Playstore) hat die DSGVO zu massiven Rückgängen in der Entwicklung neuer Apps und zum Rückzug vieler Entwickler geführt.
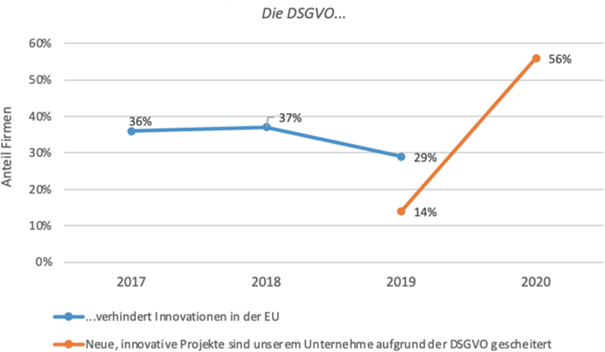
Abb. 2
(Quelle: Bitkom (2017, 2018, 2019, 2020))
Datenschutz und Innovation.
Eine sinnvolle positive wie normative Einordnung dieser Zahlen ist jedoch schwierig, da wesentliche Kontextinformationen fehlen. Zum einen muss grundsätzlich betont werden, dass nicht jede Innovation gesellschaftlich oder wirtschaftlich wünschenswert ist. Wenn eine im Vergleich zur Zeit vor der DSGVO peniblere Einhaltung von Datenschutzgesetzen heute dazu führt, dass z. B. ein Startup daran gehindert wird, sensible Finanzinformationen ungesichert zu verarbeiten oder eine Firma ein angedachtes Produkt stornieren muss, das Jobbewerbungen mit „Hintergrundinformationen“ aus den Social-Media-Profilen der Bewerber „anreichern“ sollte, dann ist das vielleicht weniger ein Hinweis darauf, dass die DSGVO Innovation unmäßig einschränkt, als dass sie vielmehr ihren Zweck erfüllt. Das Problem ist jedoch, dass weiterhin sehr wenig darüber bekannt ist, welche „neuen, innovativen Projekte“ aufgrund der DSGVO tatsächlich scheitern.
Die bereits zitierte Umfrage des Bitkom legt nahe, dass insbesondere der „Aufbau von Datenpools, z. B. um Daten mit Partnern zu teilen“ sowie der „Einsatz neuer Technologien, wie z. B. Big Data und KI“ aufgrund der DSGVO scheitern. Aber zu welchen Zwecken sollten diese Technologien bzw. Pools eingesetzt werden? In welchen Branchen sind die betroffenen Firmen aktiv und welche Geschäftsmodelle verfolgen sie? Geht es hier um die Entwicklung von Zukunftstechnologien mit erheblichem wirtschaftlichen und ökologisch-gesellschaftlichem Mehrwert, die etwa die Energie- und Verkehrswende vorantreiben könnten? Oder geht es um Online-Werbetechnologien, die Konsument:innen immer umfassender ausspähen – mit fragwürdigem gesellschaftlichen oder volkswirtschaftlichen Mehrwert?
Ebenso unklar ist, was für Folgen das Scheitern dieser „neuen, innovativen Projekte“ für die befragten Firmen hatte, und was „Scheitern“ konkret bedeutet. Ging es hier oft um strategisch wichtige Projekte, deren Scheitern die Wettbewerbsfähigkeit der Firma maßgeblich schädigt? Oder um eine Innovationsidee unter vielen, die vielleicht sogar in abgeänderter Form in einem anderen Projekt fortentwickelt wird? Wir wissen es nicht.
Dass jedoch unter den befragten Firmen der Anteil jener, der angibt, Innovationsprojekte seien wegen der DSGVO gescheitert, massiv steigt (von 14 % auf 56 % zwischen 2019 und 2020), gleichzeitig aber der Anteil derjenigen, der angibt, sie seien durch die DSGVO bedroht, zurückgeht und auf niedrigem Niveau verharrt (12 %) und der Anteil, der in der DSGVO einen allgemeinen Wettbewerbsvorteil für europäische Firmen erblickt, ebenfalls weiterhin stark wächst (von 50 % auf 62 %) legt nahe, dass die DSGVO Innovationsaktivitäten allgemein nicht in einem kritischen Ausmaß behindert.
Fast noch weniger als über die negativen Innovationsauswirkungen der DSGVO wissen wir über ihre positiven Auswirkungen. Etwa zwei Drittel der von Bitkom befragten Firmen hält sie für einen Wettbewerbsvorteil für europäische Unternehmen, wenngleich nur 20 % einen Vorteil für sich selbst erblicken. Welche konkreten Vorteile sehen diese Firmen also in der DSGVO für sich und andere? Warum ist dennoch die Hoffnung vieler Firmen, Vorteile aus der DSGVO zu ziehen, anscheinend enttäuscht worden? Schließlich hatten im Jahr 2017 noch 38 % der Befragten in ihr einen Vorteil für das eigene Geschäft gesehen. Auch auf diese Fragen gibt es soweit noch keine klaren Antworten.
Drei mögliche Wirkmechanismen, über die die DSGVO Firmen Vorteile verschaffen könnte, sind Marktvorteile, Angleichung von Wettbewerbsbedingungen und gestiegenes Verbrauchervertrauen.
Marktvorteile: Martin u. a. identifizieren in ihren Interviews einen „Buy European“-Effekt: Firmen gaben an, bei Datenschutz-relevanten Produkten neuerdings europäische Anbieter zu bevorzugen, oder sogar ganz auf außereuropäische Anbieter zu verzichten, da sie glaubten, sich bei Europäern eher darauf verlassen zu können, dass die DSGVO tatsächlich eingehalten wird. Die nach dem Schrems II-Urteil weiter gestiegenen Hürden, Daten ins außereuropäische Ausland zu transferieren, dürften diesen Effekt weiter stärken.
Zwar sind solche de facto protektionistischen Effekte grundsätzlich eher wettbewerbs-, wohlstands- und innovationsschmälernd; aufgrund der Größe des europäischen Binnenmarktes dürfte dieser Schaden aber gering bleiben. Im Gegenteil, wenn solche DSGVO-bedingten Marktvorteile das Wachstum europäischer Alternativen zu den dominierenden US-Konzernen befördern, könnten sie langfristig für mehr Wettbewerb und damit mehr Wohlstand und Innovation sorgen.
Angleichung von Wettbewerbsbedingungen: Die DSGVO bietet die Chance, einheitlichere Datenschutzstandards in Europa und potentiell sogar weltweit durchzusetzen, wenn sie von anderen Wirtschaftsregionen oder außereuropäischen Firmen teilweise übernommen wird. Dieses Phänomen, der sog. „Brussels Effect“ kann in diversen Regulierungsfeldern beobachtet werden, einschließlich dem des Datenschutzes. Das dürfte insbesondere deutschen Firmen zugutekommen, da deutsche Standards auch bisher zu den höchsten in Europa zählten. Wie Abb. 3 zeigt, erwartet eine klare Mehrheit deutscher Firmen solche Angleichungen des Datenschutzstandards und somit der Wettbewerbsbedingungen durch die DSGVO.

Abb. 3
(Quelle: Bitkom (2017, 2018, 2019, 2020))
Angleichung von Wettbewerbsbedingungen.
Verbrauchervertrauen: Verbraucherumfragen legen nahe, dass Sorgen um Datenmissbrauch weiterhin ein wichtiger Grund für die Nicht-Nutzung neuer Digitalprodukte wie z. B. Sprachassistenten sind. Interviews mit Firmenvertretern bekräftigen, dass allgemeines Konsumentenmisstrauen um „Ausspähung“ bisweilen auch rechtlich wie gesellschaftlich unproblematische Innovationen scheitern lässt, da Unternehmen davon absehen, Technologien zu nutzen oder zu entwickeln, die Verbrauchermisstrauen wecken könnten.
Regulierung ist grundsätzlich geeignet, derartige Sorgen zu nehmen und Vertrauen herzustellen. Ob die DSGVO dies bisher geschafft hat, ist indes fraglich. Die DSGVO und die in ihr verbrieften Rechte sind den meisten EU-Bürgern wenigstens in Ansätzen bekannt. 57 % (und damit 20 % mehr als 2015) wissen auch um die Existenz der Datenschutz-Aufsicht. Dieses Wissen könnte das Vertrauen der Bürger in den Schutz und die Kontrollierbarkeit ihrer Daten (und damit Technologieakzeptanz) stärken. Tatsächlich aber ist seit 2015 die Zahl der Bürger, die glauben wenigstens begrenzte Kontrolle über ihre Daten zu haben, in den meisten EU-Staaten nur unwesentlich gestiegen oder sogar gefallen. Allerdings ist auch die Zahl derer, denen diese fehlende Kontrolle Sorgen bereitet, in den meisten EU-Ländern (leicht) gefallen, wobei sie weiterhin fast überall die Mehrheit bilden. Ein Paradigmenwechsel im Hinblick auf Vertrauen zeichnet sich somit noch nicht ab. Andererseits wäre ein signifikanter Vertrauensanstieg innerhalb von ein bis zwei Jahren nach Einführung der DSGVO auch kaum zu erwarten. Vertrauen dürfte sich, wenn überhaupt, langsam und über längere Zeiträume aufbauen. Insofern erscheint es eher unwahrscheinlich, dass der Faktor „Vertrauen“ schon jetzt positive Innovationswirkungen hat.
3.2 DSGVO-Sanktionen
Eine der wesentlichsten Veränderungen im deutschen und europäischen Datenschutzregime, das die DSGVO gebracht hat, ist die Verschärfung des Sanktionsregimes. Konnte vor der DSGVO in Deutschland ein Bußgeld von maximal 300.000 EUR für einen Datenschutzverstoß verhängt werden, so sind jetzt Bußgelder von bis zu 20 Mio. EUR oder vier Prozent des weltweiten jährlichen Unternehmensumsatzes möglich. Zweck dieser massiven Erhöhung war es, das in den Vorjahren vielfach konstatierte „Vollzugsdefizit“ im Datenschutz – bzw. die auf Unternehmensseite verbreitete Wahrnehmung, dass Datenschutzverstöße nur „Kavaliers- und Bagatelldelikte“ seien – zu beheben. Entsprechend großes Interesse kam im Vorfeld daher der Frage zu, wie die Datenschutzbehörden mit den neuen Zwangsmitteln umgehen würden.
Wie die aktuelle Forschung darlegt, spielten Bußgelder in der Aufsichtspraxis und dem Amtsverständnis der deutschen Landesbehörden in der „vor-DSGVO-Zeit“ eher eine untergeordnete Rolle. Der Fokus der Behörden lag eher auf Aufklärung, Sensibilisierung und Beratung der Öffentlichkeit und der Verantwortlichen sowie auf der Bearbeitung von Eingaben und Beschwerden betroffener Personen. Gerade bei kleinen und mittleren Unternehmen wurde (und wird) der Schwerpunkt eher darauf gelegt, datenschutzkonforme Zustände (wieder-)herzustellen – und nicht, eventuelle Verstöße möglichst hart zu sanktionieren. Vorausgesetzt, dass sich Verantwortliche kooperativ und reformwillig zeigten (und Verstöße nicht vorsätzlich begangen oder die betroffenen Personen unzumutbar hohen Risiken ausgesetzt wurden), blieben Bußgelder meist niedrig oder es wurde ganz auf sie verzichtet. Dieser eher auf Sensibilisierung und Beratung als auf aktivem „Eintreiben“ von Bußgeldern fokussierte Ansatz grenzte sich auch vom aufsichtsbehördlichen Stil mancher anderer EU-Mitgliedstaaten ab, in denen Bußgeldern schon vor der Datenschutz-Grundverordnung eine wichtigere Rolle zukam, auch zur Finanzierung der Behörden.
In Interviews im Frühjahr und Sommer 2018 betonten Behördenvertreter, dass sie sich zwar einerseits verpflichtet sahen, die Spielräume des neuen Bußgeldrahmens zu nutzen und dies auch wollten, um eine bislang häufig fehlende Disziplin in den Markt zu tragen. Andererseits sahen sie aber weiterhin ihre Amtsaufgabe nicht primär im Verteilen von Bußgeldern. Ihre Botschaft lautete aber, dass bei eklatanten Missbräuchen Bußgelder künftig merkbar steigen würden, während man kooperative Akteuren, die Fehler eingestehen und abstellen wollen, konstruktiv unterstützen werde.
Wie Abb. 4 zeigt, ist die Höhe sowie die Zahl der verhängten Bußgelder dennoch erheblich angestiegen. Bewegte sich der durchschnittliche Gesamtwert der jährlich von allen deutschen Datenschutz-Aufsichtsbehörden verhängten Bußgelder in den Jahren 2010 bis 2018 noch im unteren sechsstelligen Bereich, wurden 2019 bereits Bußgelder von insgesamt mehr als 25 Mio. EUR verhängt, und im Jahr 2020 waren es bis Herbst bereits mindestens 36,5 Mio. EUR. Gleiches gilt für die Anzahl der Bußgelder. Es scheint, dass in keinem Jahr zwischen 2010 und 2018 mehr als 191 Bußgelder verhängt wurden, meist erheblich weniger als 150. Dagegen waren es 2019 bereits 494.
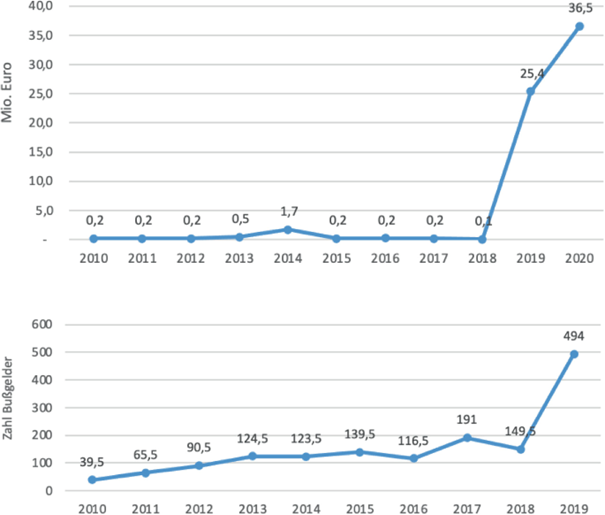
Abb. 4
(Quelle: Tätigkeitsberichte der Landes- und Bundesaufsichtsbehörden, Presseberichte)
Gesamtwert (oben) und Gesamtzahl (unten) verhängter Datenschutz-Bußgelder (Schätzwerte, jährlicher Durchschnitt).
Welche Auswirkungen dürfte die verschärfte Bußgeldpraxis auf Unternehmen haben? Wie die sozialwissenschaftliche Forschung zu Compliance-Verhalten von Firmen herausgearbeitet hat, sind die Faktoren, die in Unternehmensentscheidungen, sich an Recht und Gesetz zu halten, oder eben nicht, komplex. Neben „ökonomischen“ Erwägungen wie der erwarteten Höhe des durch Rechtsbruch zu erzielenden Gewinns diskontiert um die Wahrscheinlichkeit, entdeckt zu werden und die Schwere der zu erwartenden Strafe spielen auch Fragen gesellschaftlicher Erwartungen wie etwa Reputationsverluste sowie innere normative Vorstellungen eine wichtige Rolle.
Zwar ist mit dem höheren Bußgeldrahmen die zu erwartende Strafe im Entdeckungsfall wesentlich gestiegen, die weiterhin begrenzten Personalkapazitäten der Aufsichtsbehörden lassen die Wahrscheinlichkeit einer Entdeckung durch „Initiativfahndung“ seitens der Aufsichtsbehörden jedoch weiterhin sehr gering erscheinen. Wichtiger für die Aufdeckung dürften Eingaben und Beschwerden aus der Bevölkerung sowie ggf. von Wettbewerbern sein. Diese sind in den vergangenen zwei Jahren ebenfalls massiv gestiegen. Hohe, medienwirksame Bußgelder dürften diesen Zustrom am Laufen halten, insofern sie das Thema Datenschutz und Datenschutzverstöße in der öffentlichen Wahrnehmung halten.
Die Androhung von Sanktionen ist jedoch oft nicht der Hauptgrund, warum sich Firmen wie Einzelpersonen an Regeln halten. Im Gegenteil wollen sich die meisten Menschen und Organisationen aus innerer Überzeugung an Recht und Gesetz halten. Wie Martin et. al. ausführen, können hohe Strafen diesen Willen durchaus bestärken, nicht im Sinne der Abschreckung, sondern indem sie eine „kalibrierende“ Wirkung entfalten: Das Sanktionsmaß ist auch eine Messlatte für Bewertung des Rechtsbruchs in der Gesellschaft: Niedrige Sanktionen deuten auf Bagatelldelikte hin, die man sich auch mit gutem Gewissen „einmal leisten kann“; schwere Sanktionen auf Verfehlungen, die erhebliche moralische Schuld nach sich ziehen. Dies ist insofern relevant, als dass Datenschutzverfehlungen bislang eben doch sehr häufig als Bagatellen aufgefasst worden sind und nicht als Grundrechtsverstöße.
Der neue Bußgeldrahmen könnte helfen, diese Wahrnehmung zu verändern – vorausgesetzt, dass er tatsächlich zur dauerhaften Etablierung wesentlich höherer Bußgelder für Datenschutzverstöße führt.
Bis zu welchem Grad das tatsächlich geschehen wird, scheint bislang noch offen. Gemäß Art. 83(1) DSGVO müssen Bußgelder „in jedem Einzelfall wirksam, verhältnismäßig und abschreckend“ sein. Darüber hinaus legt die DSGVO zwei Obergrenzen für Bußgelder fest (10 bzw. 20 Mio. EUR oder 10 bzw. 20 % des konzernweiten Jahresumsatzes) (Art. 83(4)(5) DSGVO). Zudem benennt sie Kriterien, anhand derer die Schwere von Verstößen bestimmt werden kann (Art. 83(2) DSGVO) und legt zumindest grob fest, dass Verstöße gegen bestimmte Auflagen schwerer wiegen (und daher mit bis zu 20 Mio. EUR Bußgeld geahndet werden können) als andere (für die maximal 10 Mio. EUR Bußgeld fällig werden können) (Art. 83(4)(5) DSGVO). Eine Untergrenze für Bußgelder legt sie jedoch nicht fest. Festzulegen, wie hoch ein „wirksames, verhältnismäßiges und abschreckendes“ Bußgeld ist, bleibt damit letztlich der Auslegung der Aufsichtsbehörden vorbehalten – und der Rechtsprechung durch die Gerichte. Wie oben ausgeführt, sind die Datenschutzbehörden offensichtlich Willens, wesentlich höhere Bußgelder zu verhängen. Die kritische – soweit noch nicht beantwortbare – Frage ist, inwiefern die Gerichte dies mittragen werden. Zumindest in einem Fall – dem 9,55 Mio. EUR Bußgeld des Bundesdatenschutzbeauftragten gegen den Telefonanbieter 1&1 – hat das Gericht ein sehr hohes Bußgelder um 90 % (!) reduziert, was vom Bundesbeauftragten akzeptiert wurde. Inwiefern diesem Fall breitere Bedeutung zukommt, bleibt abzuwarten; was er aber verdeutlicht, ist dass die DSGVO einen Prozess der „Rekalibrierung“ der rechtlichen wie moralischen Schwere von Datenschutzverstößen eingeleitet hat, in dem wir uns noch befinden. Das tatsächlich zu erwartende Strafmaß bei Verstößen liegt damit noch im Fluß.
4 Schluss
Als die Kommission im Jahre 2012 ihren DSGVO-Entwurf vorlegte, wurden mehrere ambitionierte Ziele ins Auge gefasst: Die neue Verordnung sollte nicht nur neue innovative datenschutzrechtliche Instrumente wie die DSFA einführen, sie sollte auch den datenschutzrechtlichen Rahmen über alle EU-Mitgliedstaaten hinweg harmonisieren und zukunftstaugliche, technikneutrale Formulierungen enthalten. Damit sollte die DSGVO letzten Endes ein wirkungsvolles, neues Datenschutz-Regime etablieren, das Innovationen fördert, sofern sie keine Einschränkung des EU-Grundrechts auf Datenschutz darstellen, während zugleich mittels des neuen Sanktionsregimes böswillige Akteure von Zuwiderhandlungen abgehalten werden sollten.
Da im Hinblick auf die Aspekte der Harmonisierung und Technikneutralität bereits zum Zeitpunkt der Verabschiedung der DSGVO ein Nichterreichen der selbstgesteckten Ziele attestiert wurde, hat sich der vorliegende Beitrag im Rahmen der ersten Frage der Frage gewidmet, weshalb die Einführung datenschutzrechtlicher Innovationen durch eine unzureichende Harmonisierung und eine falsch verstandene Technikneutralität begleitet wurde. Im Rahmen der zweiten Frage wurde hingegen untersucht, welche Effekte die DSGVO auf die Innovationsfähigkeit hat und wie das neue Sanktionsregime wirkt.
Obwohl die Europäische Kommission für die vorgesehene Kompetenzverlagerung hin zur Kommission selbst während der Datenschutzreform viel gescholten wurde, hätten die initialen Kommissionsvorschläge als auch die späteren Alternativvorschläge von Kommission und Parlament die flexible Anpassung und Spezifizierung der Datenschutz-Bestimmungen an die Datenschutz-Risiken künftiger Technologien erlaubt. Dadurch wäre zudem die Wahrscheinlichkeit reduziert worden, dass bei künftigen Spezifizierungsdebatten gleich die Neuverhandlung der gesamten Verordnung aufs Tablett gebracht wird oder gar, dass sich bei einer vollumfänglichen Reform die Perspektive der Gegner eines hohen Datenschutzniveaus durchsetzen könnte, wie es in der Datenschutzpolitik regelmäßig der Fall gewesen ist und wie es auch im Falle der DSGVO wahrscheinlich der Fall gewesen wäre, wenn sich die Community der Datenschutzbefürworter einer Absenkung des Schutzniveaus nicht entschieden entgegengestellt und wenn die Snowden-Enthüllungen ihren Argumenten keinen Auftrieb verschafft hätten.
In Summe wurde die DSGVO durch die Streichung der delegierten und Durchführungsrechtsakte sowohl der wirksamen Gewährleistung der Harmonisierung als auch der Möglichkeit zur Adressierung technologie-spezifischer Risiken beraubt, ohne dass im Rahmen des Trilogs geeignete Alternativen beschlossen wurden. Weder die von der Kommission vorgeschlagene Selbstermächtigung noch die vom Parlament vorgeschlagene Spezifizierung im Verordnungstext selbst konnten sich angesichts des Widerstands des Ministerrats durchsetzen.
Die mangelnde Harmonisierung des europäischen Datenschutzrechts und die Verabschiedung einer falsch verstandenen Technikneutralität, die als Risikoneutralität wirkt, sind somit Ergebnis des Widerstands des Ministerrats bzw. der darin versammelten Mehrheit der Mitgliedstaaten, die historisch stets gegen die EU-weite Harmonisierung der datenschutzrechtlichen Regelungen eingetreten waren. Dies lässt die Hoffnung darüber, dass sich auf Ebene und unter der Verantwortung der Mitgliedstaaten mittels der Öffnungsklauseln etc. eine Anhebung des Schutzniveaus durchsetzen ließe, aussichtslos erscheinen.
Die Analyse der Wirkung der DSGVO hat gezeigt, dass es klare Hinweise darauf gibt, dass die DSGVO Innovationshindernisse schafft. Da der allgemein als legitim anerkannte Zweck der DSGVO allerdings auch gerade darin liegt, bestimmte Datenverarbeitungen (somit auch Innovationen) auszubremsen, um Rechte und Freiheiten der Betroffenen zu schützen, ist dies an sich nicht problematisch, sondern kann im Gegenteil als Beleg für die Wirksamkeit der DSGVO gewertet werden. Problematisch wäre jedoch, wenn die DSGVO die Entwicklung wichtiger Zukunftstechnologien, die etwa für die Sicherung des Wohlstandes oder den ökologischen Umbau von Wirtschaft und Gesellschaft benötigt werden, ausbremsen würde. Die wenigen Studien suggerieren aber, dass große Mehrheiten deutscher Firmen die DSGVO eher als Wettbewerbsvorteil denn als -nachteil sieht. Dies kann als Hinweis interpretiert werden, dass sie strategisch wichtige Innovation eher nicht in einem kritischen Ausmaß behindert. Aufgrund der begrenzten Datenlage sind dies jedoch letztlich Spekulationen. Wir brauchen daher detailliertere, branchen- und technologiespezifische Studien zu den Auswirkungen des Datenschutzes auf Innovation.
Der neue Sanktionsrahmen wird zunehmend von den deutschen Datenschutzbehörden angewandt. Bußgelder in Millionenhöhe werden verhängt. Die bislang verbreiteten Wahrnehmungen (i) eines „Vollzugsdefizits“ im Datenschutz und dass (ii) Datenschutzverstöße Bagatelldelikte seien, dürften somit mehr und mehr der Vergangenheit angehören. Gleichzeitig ist davon auszugehen, dass die Aufsichtsbehörden ihre Amtsaufgabe weiterhin primär nicht in der Verhängung von Bußgeldern sehen werden.
Die mit großen Ambitionen gestartete Datenschutz-Grundverordnung befindet sich nun seit mehreren Jahren in der Anwendung und wie sich zeigt, ist sie weder der ambitionierte Heilsbringer für die Europäische Digitalwirtschaft, wie sie während des Aushandlungsprozesses immer wieder beworben wurde, noch ist sie die vonseiten vieler Mitgliedstaaten und der datenverarbeitenden Wirtschaft befürchtete massive Innovationsbremse, die Europa aus dem Rennen um technologische Hoheit wirft. Stattdessen zeigt sich, dass die DSGVO komplexe Effekte entfaltet, die noch weiterer Untersuchung und Konkretisierung bedürfen.
CC BY
Karaboga, M., Martin, N., Friedewald, M. (2022). Governance der EU-Datenschutzpolitik. In: Roßnagel, A., Friedewald, M. (eds) Die Zukunft von Privatheit und Selbstbestimmung. DuD-Fachbeiträge. Springer Vieweg, Wiesbaden.
https://doi.org/10.1007/978-3-658-35263-9_2
Zur einfacheren Lesbarkeit wurden die Quellenverweise und Fussnoten entfernt.